
KNN алгоритм гэж юу вэ?
K-Nearest Neighbors (KNN) алгоритм нь хяналттай машин сургалтын ангилал (classification) болон регресс (regression)-ийн бодлогыг шийдэхэд ашиглагддаг энгийн боловч үр дүнтэй арга юм. Энэ алгоритм нь параметргүй бөгөөд lazy learning төрөлд хамаардаг. Өөрөөр хэлбэл сургалтын явцад тусгай загвар сургахгүй, харин өгөгдлийг хадгалж, шинэ өгөгдөл орж ирэх үед шууд харьцуулалт хийж таамаглал гаргадаг.
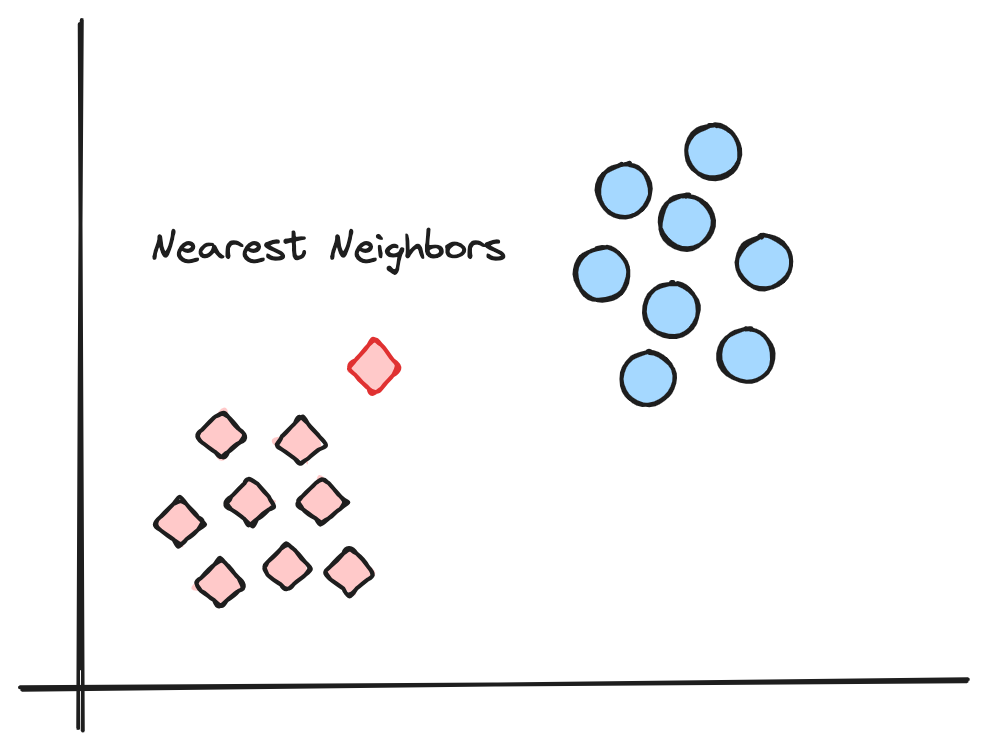
KNN алгоритмын үндсэн зарчим нь төстэй өгөгдлүүд хоорондоо ойрхон байрладаг гэсэн ойлголт дээр тулгуурладаг.

KNN алгоритм дараах үндсэн алхмуудаар ажиллана:
- K утгыг сонгох
K нь шинэ өгөгдлийг үнэлэхдээ хэдэн хамгийн ойр хөршийг авч үзэхийг илэрхийлнэ. - Зайг тооцоолох
Шинэ өгөгдөл болон сургалтын өгөгдөл бүрийн хоорондын зайг тодорхойлно. Ихэвчлэн Евклидийн зайг ашигладаг. - Хамгийн ойр K хөршийг сонгох
Тооцоолсон зайнаас хамгийн бага утгатай K ширхэг өгөгдлийг сонгоно. - Таамаглал хийх
- Ангилал: K хөршүүдийн дунд хамгийн олон давтагдсан ангийг сонгоно
- Регресс: K хөршүүдийн утгын дунджийг авна
KNN алгоритмыг дараах байдлаар ашигладаг:
- Өгөгдлийг цуглуулж, ангилал эсвэл тоон утгатай шошголно
- Өгөгдлийг масштаблах (normalization, standardization)
- K утгыг сонгох (ихэвчлэн cross-validation ашиглана)
- Шинэ өгөгдөлд таамаглал хийх
KNN нь өгөгдөл дээр шууд ажилладаг тул сургалтын хугацаа бараг шаарддаггүй.

K утгыг зөв сонгох нь KNN алгоритмын гүйцэтгэлд шууд нөлөөлдөг чухал хүчин зүйл юм. K нь шинэ өгөгдлийг үнэлэхдээ хэдэн хамгийн ойр хөршийг авч үзэхийг илэрхийлнэ. Хэрэв K хэт бага байвал алгоритм дуу чимээ (noise)-д мэдрэмтгий болж, санамсаргүй өгөгдөлд буруу ангилалт хийх магадлал нэмэгддэг. Харин K хэт их байвал орон нутгийн онцлогийг үл тоомсорлож, өөр өөр ангиудыг холилдуулах эрсдэлтэй. Иймээс практикт K утгыг туршилтаар тодорхойлж, ихэвчлэн cross-validation ашиглан хамгийн өндөр нарийвчлал өгдөг K-г сонгодог.
KNN алгоритмын давуу тал
- Ойлгоход хялбар, хэрэгжүүлэхэд энгийн
- Сургалтын шат шаарддаггүй
- Олон төрлийн зай хэмжих аргыг ашиглах боломжтой
- Ангилал болон регрессийн аль алинд хэрэглэж болно
- Жижиг өгөгдөл дээр сайн үр дүн өгдөг
KNN алгоритмын сул тал
- Том өгөгдөл дээр тооцооллын зардал ихтэй
- Санах ой их шаарддаг
- Шинж чанарын масштабад маш мэдрэмтгий
- Өндөр хэмжээст өгөгдөл дээр үр ашиг мууддаг
- Дуу чимээ (noise)-д мэдрэмтгий
KNN алгоритмын хэрэглээ (Use cases)
KNN алгоритм дараах салбаруудад өргөн хэрэглэгддэг:
- Зураг ангилал (image recognition)
- Хээ таних (pattern recognition) гэх мэт олон олон хэрэглээ бий.
K-Nearest Neighbors (KNN) алгоритм нь ойлгоход хялбар, хэрэгжүүлэхэд энгийн бөгөөд олон төрлийн бодлогод ашиглаж болох машин сургалтын суурь арга юм. Хэдийгээр том өгөгдөл болон өндөр хэмжээст орчинд үр ашиг нь буурдаг ч, жижиг болон дунд хэмжээний өгөгдөл дээр, мөн суурь алгоритм болгон ашиглахад маш тохиромжтой. Иймээс KNN нь машин сургалтыг судалж эхэлж буй хүмүүст чухал ач холбогдолтой алгоритм гэж үздэг.