
The Essential Engineering Education
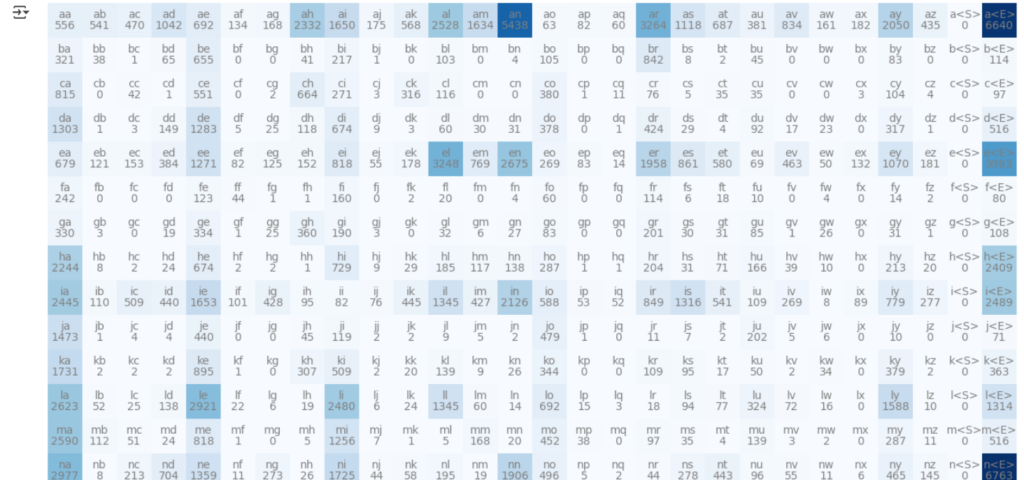
Хэлний загварчлалын: Bigram Model
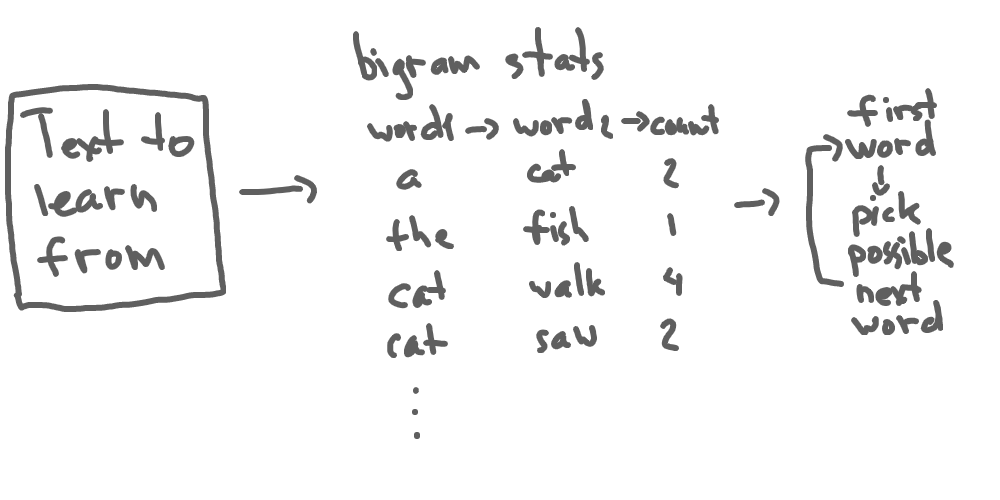



Speech recognition vs Voice recognition 2026-03-14

Decision Tree-ээс Random Forest хү� 2026-03-13

The Essential Engineering Education