
Мэдээллийн хэмжээ өдөр ирэх тусам нэмэгдэж, байгууллагууд төрөл бүрийн өгөгдөл цуглуулдаг болсон. Эдгээр мэдээллийг нэг дор төвлөрүүлэн хадгалах хэрэгцээ бий болжээ. Энэ асуудлыг шийдэх нэг оновчтой арга бол Data Lake ашиглах явдал юм. Data Lake нь боловсруулалт хийгдээгүй (raw) бүх төрлийн өгөгдлийг ямар ч ялгалгүйгээр хадгалах зориулалттай орчин юм. Жишээ нь, Excel файл, зураг, бичлэг, лог файл гэх мэт олон төрлийн өгөгдлийг нэг газарт байрлуулж болно. Ингэснээр шаардлагатай үед тухайн өгөгдлийг боловсруулж, шинжилж ашиглах боломжтой болдог.
Data Lake-ын үндсэн ойлголтууд
Data Lake нь мэдээллийг шууд боловсруулалгүйгээр яг байгаа чигээр нь хадгалдаг онцлогтой. Энэ нь тухайн мэдээлэл ямар нэгэн хүснэгт, тодорхой загварт ороогүй гэсэн үг юм. Жишээлбэл, Facebook-ийн зураг, Word баримт, камерын бичлэг зэрэг олон төрлийн файлыг хэлбэр харгалзахгүйгээр хадгалж болно. Хэрэглэгч тухайн үед боловсруулалт хийхгүй, харин шаардлагатай үедээ мэдээлэлд тохирох загвар (schema) үүсгэн ашиглана. Энэ аргыг “schema-on-read” гэж нэрлэдэг. Ийм байдлаар Data Lake нь ямар ч төрлийн мэдээлэл хадгалах уян хатан боломж олгодог бөгөөд цаашид төрөл бүрийн хэрэгцээнд ашиглах нөхцөлийг бүрдүүлдэг.
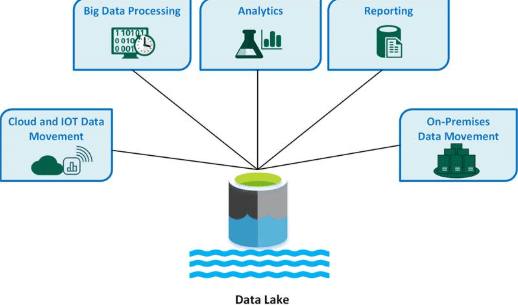
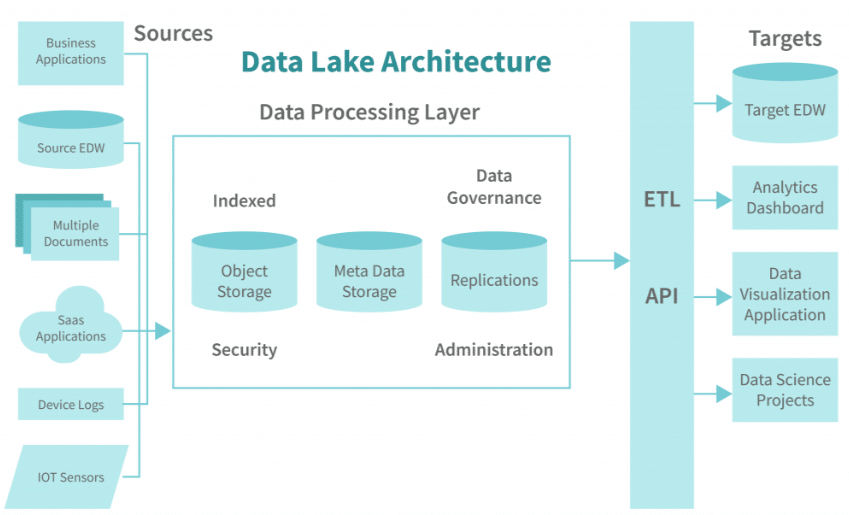
Data Lake-ийн архитектур
Data Lake нь дөрвөн үндсэн үе шаттай архитектуртай байдаг. Эхний үе шат нь өгөгдөл цуглуулах хэсэг бөгөөд энэ шатанд төрөл бүрийн эх сурвалжаас (жишээ нь IoT төхөөрөмж, програм хангамж, хэрэглэгчийн аппликейшн) мэдээллийг цуглуулдаг. Хоёр дахь үе шат бол өгөгдөл хадгалах хэсэг бөгөөд цугларсан бүх төрлийн мэдээллийг боловсруулаагүйгээр хадгална. Гурав дахь үе шат нь өгөгдөл боловсруулах хэсэг бөгөөд шаардлагатай үед өгөгдөлд загвар (schema) тавьж боловсруулдаг. Эцэст нь өгөгдөл ашиглах шатанд дата шинжилгээ, AI/ML загвар боловсруулах, BI тайлан гаргах зэрэг зорилгоор ашиглана. Энэ архитектур нь Data Lake-г уян хатан, өргөтгөх боломжтой болгодог бөгөөд олон төрлийн хэрэглээнд нэгэн зэрэг ашиглах боломжийг бүрдүүлдэг.
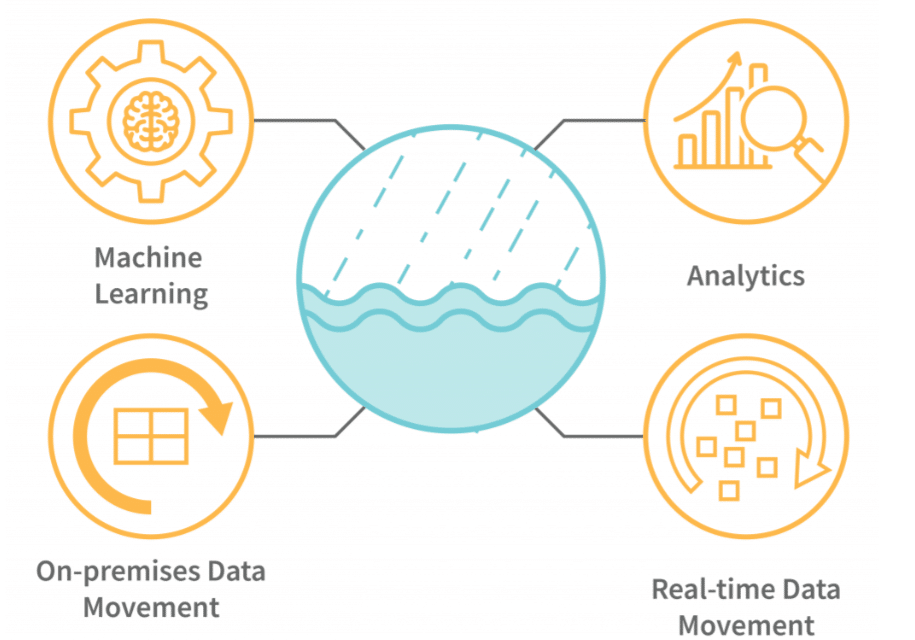
Давуу болон сул талууд
Data Lake-ийн хамгийн том давуу тал бол төрөл харгалзахгүйгээр бүх мэдээллийг нэг дор хадгалах боломж юм. Мөн ирээдүйд хэрэг болж магадгүй мэдээллийг устгахгүйгээр хадгалах нөхцөл бүрдүүлдэг. Харьцангуй бага зардлаар их хэмжээний өгөгдөл хадгалах боломжтой байдаг нь бас нэг давуу тал. Гэхдээ зохион байгуулалт муу, хяналт сул байвал Data Lake нь “Data Swamp” буюу хэрэгцээгүй, эмх замбараагүй мэдээллийн сан болж хувирч болзошгүй. Ийм үед мэдээлэл хайж, боловсруулахад их цаг хугацаа, хүч хөдөлмөр шаардагддаг сөрөг талтай.
Data Lake-д хэрэглэгддэг технологиуд
Data Lake байгуулахад олон төрлийн технологи ашиглагддаг. Тухайлбал, Hadoop, AWS S3, Azure Data Lake зэрэг нь маш их хэмжээний мэдээлэл хадгалах зориулалттай платформууд юм. Мөн Databricks, Apache Spark зэрэг хэрэгслээр Data Lake дахь мэдээллийг боловсруулж, шинжилгээ хийж болно. Metadata буюу мэдээллийн тайлбар, таних тэмдэг ашигласнаар мэдээлэл хайх, хянах, хамгаалах боломжтой болдог. Ингэснээр Data Lake дэх өгөгдөл алдагдахгүй, илүү зохион байгуулалттай болж өгдөг.
Дүгнэлт
Data Lake нь төрөл бүрийн мэдээллийг боловсруулаагүй байдлаар хадгалж, хэрэгцээ гарсан үед нь боловсруулж ашиглах боломж олгодог. Энэ нь байгууллагуудад мэдээллээ алдахгүй хадгалах, ирээдүйд олон төрлийн зорилгоор ашиглах таатай нөхцөл бүрдүүлдэг. Гэвч зохион байгуулалт муу бол мэдээлэл дунд төөрөх, хайлт хийхэд хүндрэлтэй болох эрсдэлтэй. Тиймээс Data Lake-г зөв удирдаж, мэдээлэлд хяналт тавих нь чухал. Ингэж чадвал Data Lake нь дата-д суурилсан шийдвэр гаргах, шинэ боломж хайх үр дүнтэй хэрэгсэл болж чадна.


