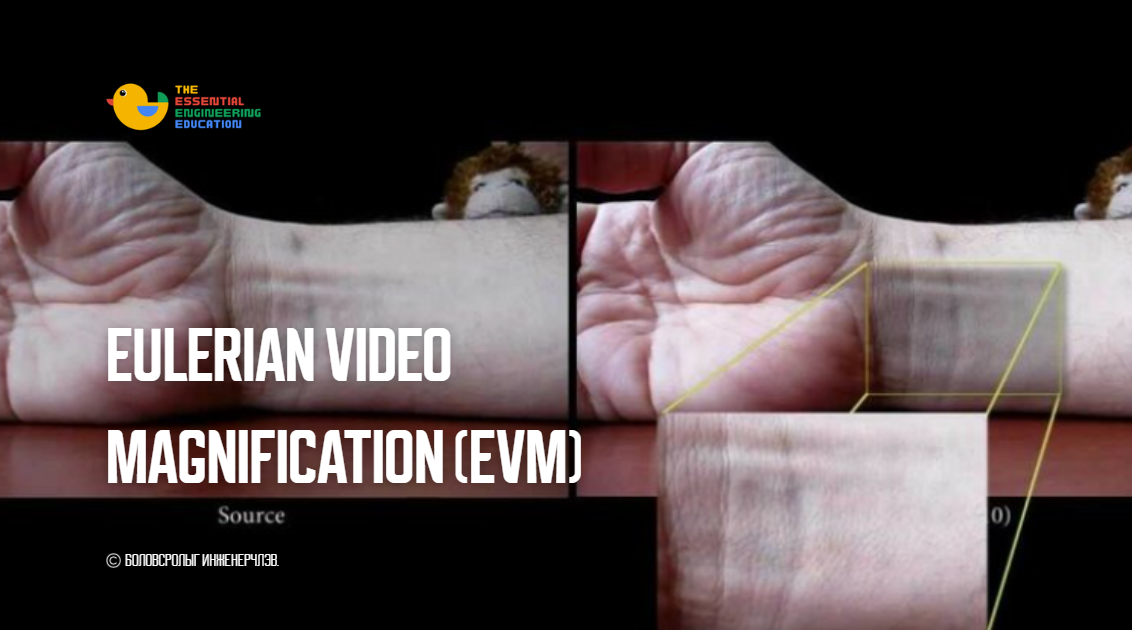
Та зураг харлаа гэж бодъё. Тэр зураг дээр нохой байна уу, муур байна уу гэдгийг хүн амархан ялгаж чадна. Гэтэл машин, компьютер үүнийг ойлгохын тулд “зураг дотор байгаа мэдээллийг” утгатай өгөгдөл болгон хувиргах хэрэгтэй болдог. Энэ процессыг Feature Extraction гэж нэрлэдэг.
Энгийнээр хэлбэл, feature extraction гэдэг нь “компьютерт мэдээллийг ойлгож болохуйц хэлбэрт оруулах” ухаалаг алхам юм. Энэ нь машиныг “харах”, “сонсох”, “унших” чадвартай болгохын суурь юм.
Яагаад чухал гэж?
Машин сургалтын (Machine Learning) загварууд нь түүхий өгөгдлийг шууд ойлгож чаддаггүй. Тиймээс хамгийн гол алхам нь: тухайн өгөгдлөөс гол шинж чанарууд буюу features-ийг ялгаж авах.
Жишээ нь:
- Зураг: өнгө, хэлбэр, ирмэг
- Текст: үгс, үгийн давтамж
- Дуу: давтамж, хэмнэл
- Тоон мэдээлэл: нас, цалин, оноо гэх мэт
Энэ нь яг л олон мянган эвлүүлдэг тоглоом дундаас хэрэгтэй хэсгүүдийг ялгаж аваад, зураг эвлүүлж эхэлж буйтай адил юм.
Feature Extraction түгээмэл технологиуд
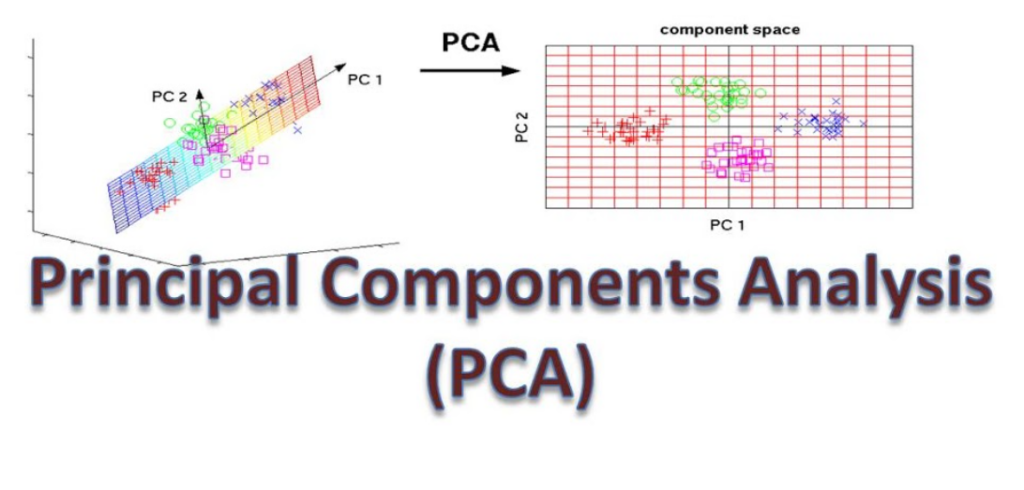
1. PCA — Ялгаатай хэсгийг нь олох арга – Principal Component Analysis (PCA) гэдэг нь олон багана, олон тооны мэдээлэл дундаас хамгийн чухал “хэлбэр, зүг чиг”-ийг олох арга юм. Төсөөлөөд үз: танд 100 баганатай Excel файл байна. Гэтэл PCA энэ 100-г нэгтгээд 2-3 шинэ багана гаргаад, бараг бүх чухал мэдээллийг хадгалсан байх болно. Ингэснээр компьютер илүү хурдан, ойлгомжтойгоор өгөгдлийг боловсруулж чадна.
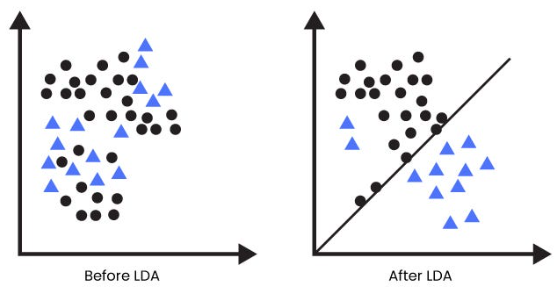
2. LDA — Ангилал тус бүрийн онцлогийг ялгаж өгөх арга – Linear Discriminant Analysis (LDA) нь “энэ зураг нь нохой юу, муур уу?” гэдгийг тодорхойлоход тохиромжтой. PCA бол ерөнхий хэв шинжийг хардаг бол, LDA нь аль ангилалд ямар ялгаа байна вэ? гэдэгт анхаардаг. Хамгийн сайн ялгаатай чиглэлүүдийг сонгож, машинд “ангилах дүрэм” гаргаж өгдөг.
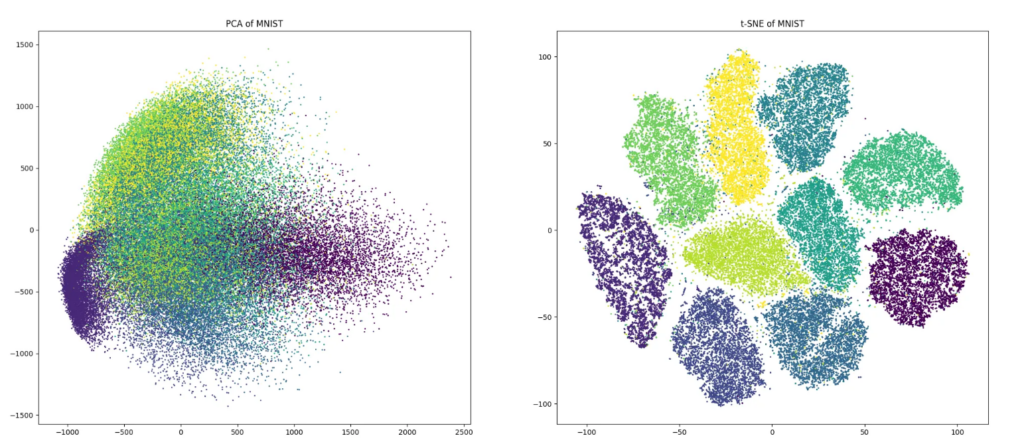
3. t-SNE — Машин ойлгохыг хүний нүдээр харах – t-SNE (t-distributed stochastic neighbor embedding) гэдэг нь өгөгдлийн дотоод бүтэц, хамаарлыг “зураг шиг” харуулж өгдөг арга. Та сая сая тоо бүхий хүснэгт харах биш, ижил төстэй зүйлс ойрхон, өөр зүйлс хол байрласан зураг хэлбэрээр харах боломжтой болдог. Энэ нь дүрслэл хийхэд маш ашигтай боловч алгоритм нь жаахан удаан.
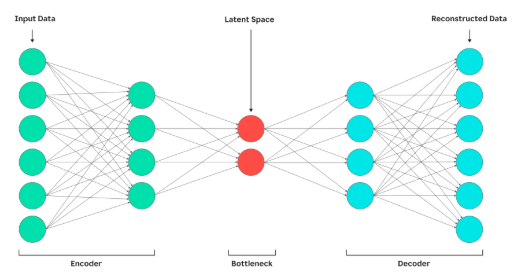
4. Autoencoder — Машин өөрөө “хурааж”, дахин сэргээдэг ухаалаг сүлжээ. Autoencoder нь нейрон сүлжээ дээр суурилсан бөгөөд өөрөө л өгөгдлөөс чухал мэдээллийг ялгаж, дахин сэргээж чаддаг. Жишээлбэл, 100×100 пиксел бүхий зургийг 20 ширхэг “багц” мэдээлэлд шахаад, дараа нь бараг анхны зурагтай ойролцоо сэргээж чаддаг. Энэ “шахсан мэдээлэл” нь машинд сурахад хамгийн хэрэгтэй онцлог шинжүүд байдаг.
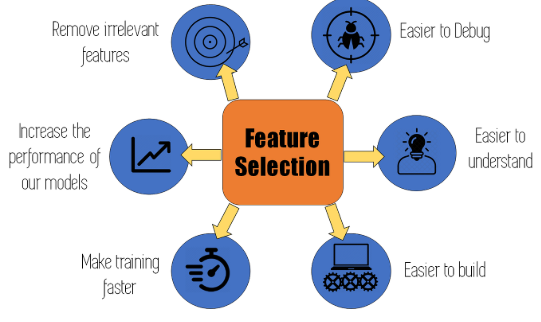
6. Feature Selection — Бүгдийг шахах биш, хамгийн чухлыг нь үлдээх – Feature Extraction бол шинээр “тулгуур” шинж үүсгэх арга бол, Feature Selection нь өгөгдөл дундаас аль шинж нь хамгийн чухал вэ гэдгийг шүүх, ялгах арга юм. Жишээ нь: нэг оюутны судалгаанд “нас, хүйс, ирц, фэйсбүүк хэрэглээ” зэрэг олон багана байж болно. Гэтэл “фэйсбүүк хэрэглээ” шалгалтын оноонд нөлөөлдөггүй бол түүнийг хасаж болно. Ийм аргаар машины анхаарлыг зөв мэдээлэл рүү чиглүүлдэг.
Дүгнэлт
Feature Extraction нь машин сургалтын гол цөм бөгөөд “машинд харах нүд, сэтгэх логик” олгодог. Зөв шинж чанаргүй бол хамгийн сайн алгоритм ч ажиллахгүй.
Иймээс “машин сургалт = зөв өгөгдөл + зөв шинж чанар + зөв алгоритм” гэдгийг ойлгох хэрэгтэй. Машин бол бидний өгсөн өгөгдлөөр л “сурна”. Харин өгөгдлийг утгатай, ойлгомжтой болгох алхам бол Feature Extraction юм.
Эх сурвалжууд
https://domino.ai/data-science-dictionary/feature-extraction
https://www.ibm.com/think/topics/feature-extraction
https://www.datacamp.com/tutorial/feature-extraction-machine-learning