
Jaeger бол орчин үеийн backend системийг дотроос нь “харах” боломж олгодог distributed tracing хэрэгсэл юм. Өнөөдрийн программ хангамжийн ихэнх системүүд олон сервис, олон давхарга, олон сүлжээний дуудлагатай болсон тул нэг хэрэглэгчийн request систем дотор хэрхэн аялж байгааг ойлгох нь улам хэцүү болж байна. API удаан ажиллаж байгааг мэдэх амархан боловч яг хаана, яагаад удааширч байгааг олох нь ихэнхдээ таамаг дээр суурилдаг. Jaeger энэ таамгийг баримтаар солих зорилготойгоор бүтээгдсэн.
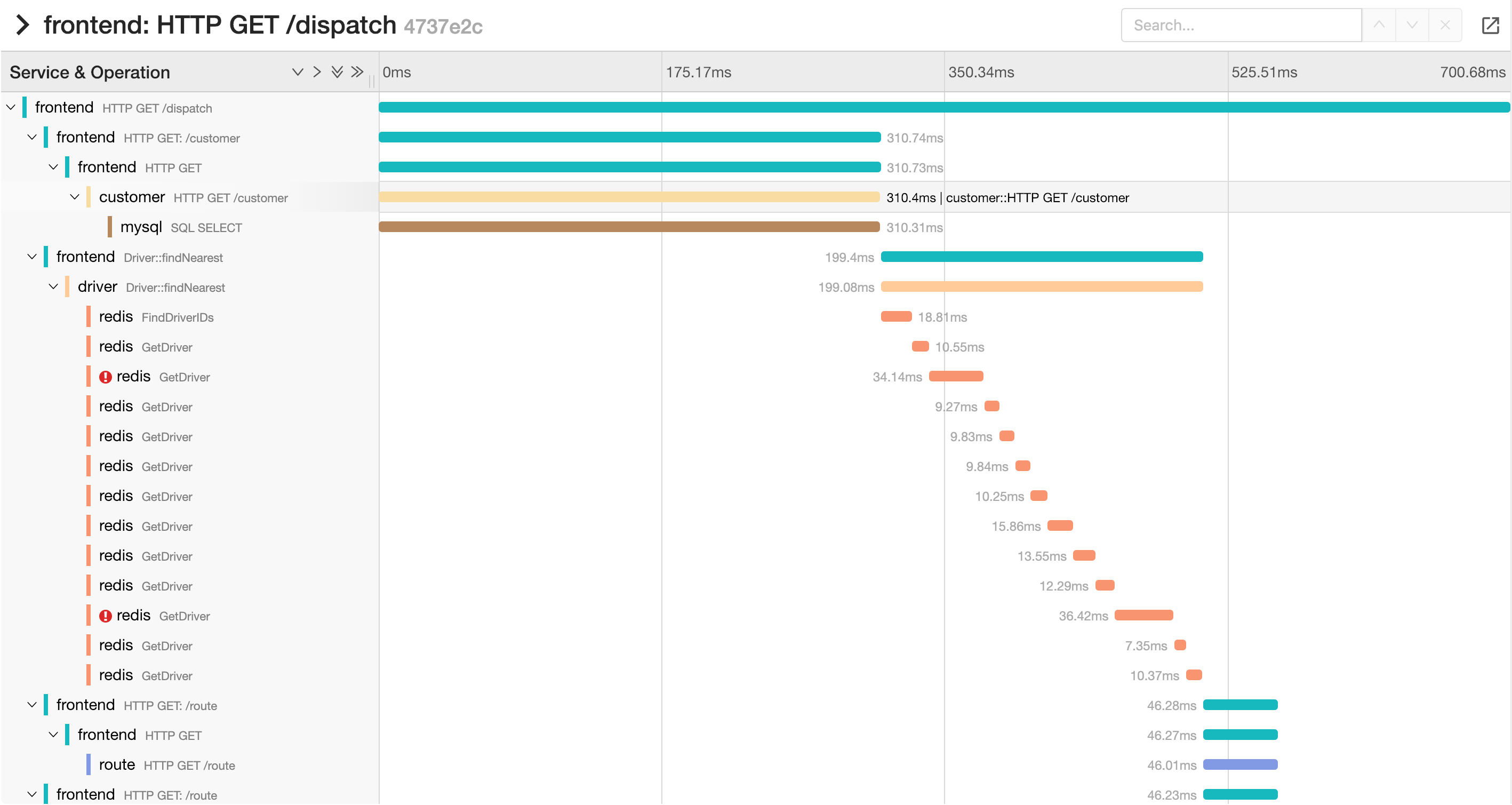
Jaeger-ийн гол ойлголт нь trace юм. Нэг хэрэглэгчийн илгээсэн request frontend-ээс эхлээд API gateway, authentication сервис, бизнес логик бүхий сервис, database, гадны API зэрэг олон бүрэлдэхүүн хэсгээр дамждаг. Jaeger энэ бүх дамжлагыг нэг trace дотор цуглуулж, аль сервис хэдэн миллисекунд зарцуулсан, аль хэсэг дээр алдаа гарсан, аль дуудлага хамгийн их саатал үүсгэж байгааг нарийн дарааллаар нь харуулдаг. Энэ нь log шиг текстэн мэдээлэл биш, metrics шиг дундаж тоо ч биш, харин нэг request-ийн амьдралын түүх юм.
Орчин үеийн observability ойлголтод metrics, logs, traces гэсэн гурван тулгуур байдаг. Metrics нь системийн ерөнхий байдал, CPU, latency, throughput зэрэг тоон хэмжүүрийг өгдөг бол logs нь болсон үйл явдлыг текст хэлбэрээр тэмдэглэдэг. Харин traces нь “яагаад” гэдэг асуултад хариулдаг. Систем яагаад удаашрав, яагаад зөвхөн зарим request алдаа өгч байна вэ гэдгийг Jaeger-гүйгээр ойлгоход маш төвөгтэй. Jaeger ашигласнаар эдгээр асуултад бодит жишээ, бодит урсгалаар хариулж чадна.
Jaeger хэрхэн ажилладаг вэ гэвэл application дээр instrumentation хийснээр эхэлнэ. Ихэнх тохиолдолд OpenTelemetry SDK ашиглан request бүрт trace id үүсгэж, сервис хооронд дамжихдаа энэ trace id-г хадгалж явуулна. Ингэснээр нэг request хэдэн сервисээр дамжсан ч нэг trace дотор холбогдож үлддэг. Энэ мэдээлэл Jaeger collector руу илгээгдэж, улмаар Jaeger UI дээр график хэлбэрээр харагдана. Инженерүүд UI дээрээс нэг trace-ийг нээгээд, аль span хамгийн удаан үргэлжилсэн, аль хэсэг дээр алдаа гарсныг яг таг харж чадна.
Жишээ нь хэрэглэгч нэг товч дарснаар frontend-ээс request явж, API gateway 20 миллисекунд, authentication сервис 15 миллисекунд, user сервис 120 миллисекунд, PostgreSQL 95 миллисекунд зарцуулсан гэж бодъё. Jaeger UI дээр энэ бүх мэдээлэл нэг босоо timeline дээр харагдана. Үүнээс user сервис удаашралын гол шалтгаан болж байгааг, тэр дундаа database query хамгийн их цаг авч байгааг хэдхэн секундийн дотор ойлгож болно. Ийм ойлголтыг зөвхөн log уншиж, эсвэл metrics хараад олоход хэдэн цаг, заримдаа хэдэн өдөр ч зарцуулдаг.
Гэхдээ Jaeger бүх төсөлд заавал хэрэгтэй гэсэн үг биш. Нэг энгийн CRUD сервис эсвэл эхний шатны MVP дээр Jaeger оруулах нь YAGNI зарчимд харшилж болзошгүй. Харин microservice архитектуртай систем, background job, worker бүхий backend, payment болон transaction шиг latency мэдрэмтгий системүүд дээр Jaeger бодит үнэ цэнээ харуулдаг. Ийм системүүдэд асуудал гарах үед хурдан оношлох нь бизнесийн хувьд асар чухал байдаг.
Senior түвшний инженерүүд Jaeger-ийг ихэвчлэн production incident үед ашигладаг. Асуудал гарахад таамаг дэвшүүлж маргахын оронд trace-ийг нээгээд бодит баримтаар ярьдаг. Аль сервис буруутай, аль өөрчлөлт latency нэмсэн, аль deploy-оос хойш асуудал эхэлснийг Jaeger маш тодорхой харуулж чаддаг. Мөн postmortem бичихэд Jaeger-ийн trace-үүд хамгийн хүчтэй нотолгоо болдог.
Эцэст нь хэлэхэд, хэрвээ чи системээ харж чадахгүй бол түүнийг бүрэн ойлгож чадахгүй. Jaeger бол системийг илүү гоё харагдуулах хэрэгсэл биш, харин илүү ухаалгаар debug хийх, илүү хурдан шийдвэр гаргах боломж олгодог хэрэгсэл юм. Backend инженерийн хувьд Jaeger-ийг ойлгож, зөв үед нь ашиглаж сурна гэдэг нь дараагийн шат руу ахих том алхам болдог.
