
The Essential Engineering Education
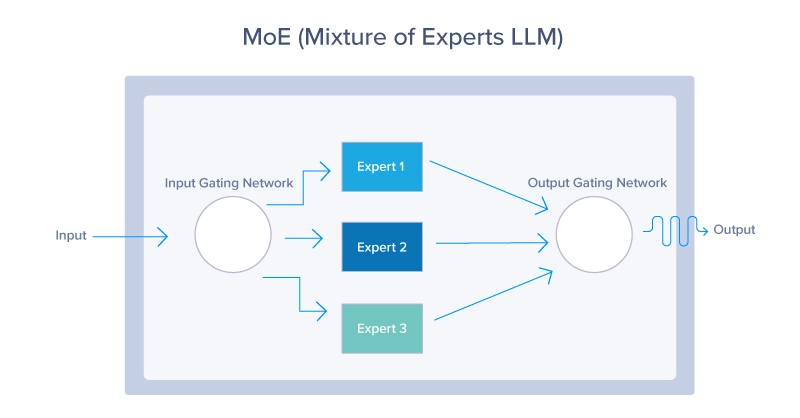
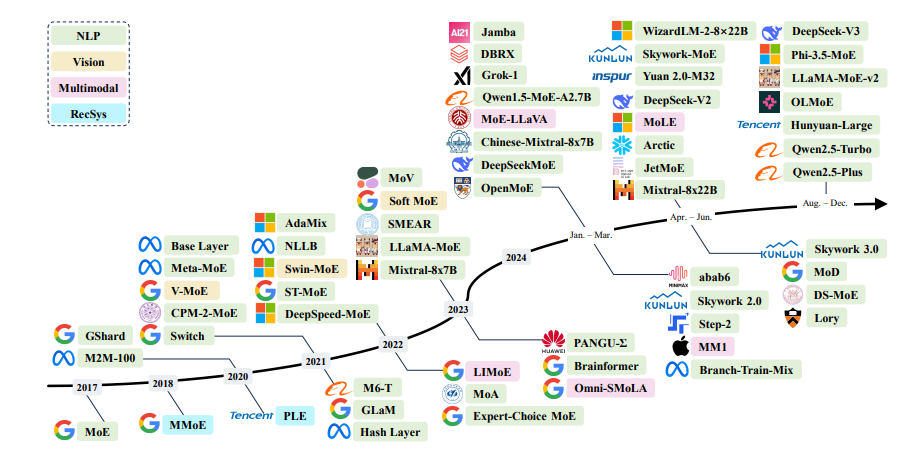
Mixture of Experts (MoE) гэж юу вэ?


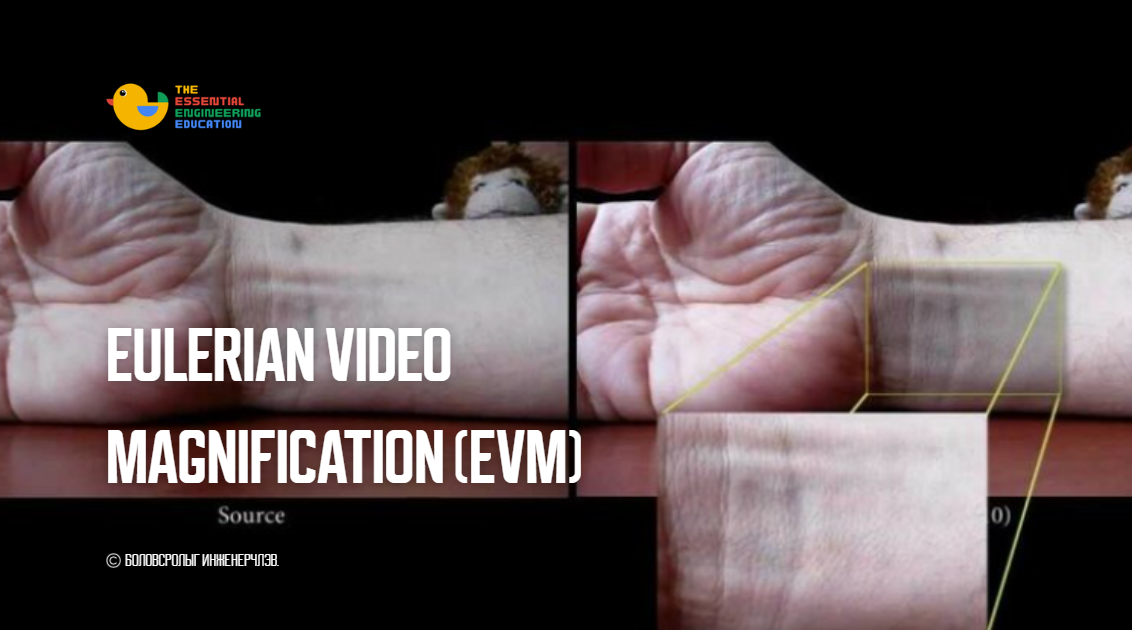
Eulerian Video Magnification (EVM) бу� 2026-01-26

Хамтдаа бодоцгооё №6 2026-01-25

The Essential Engineering Education