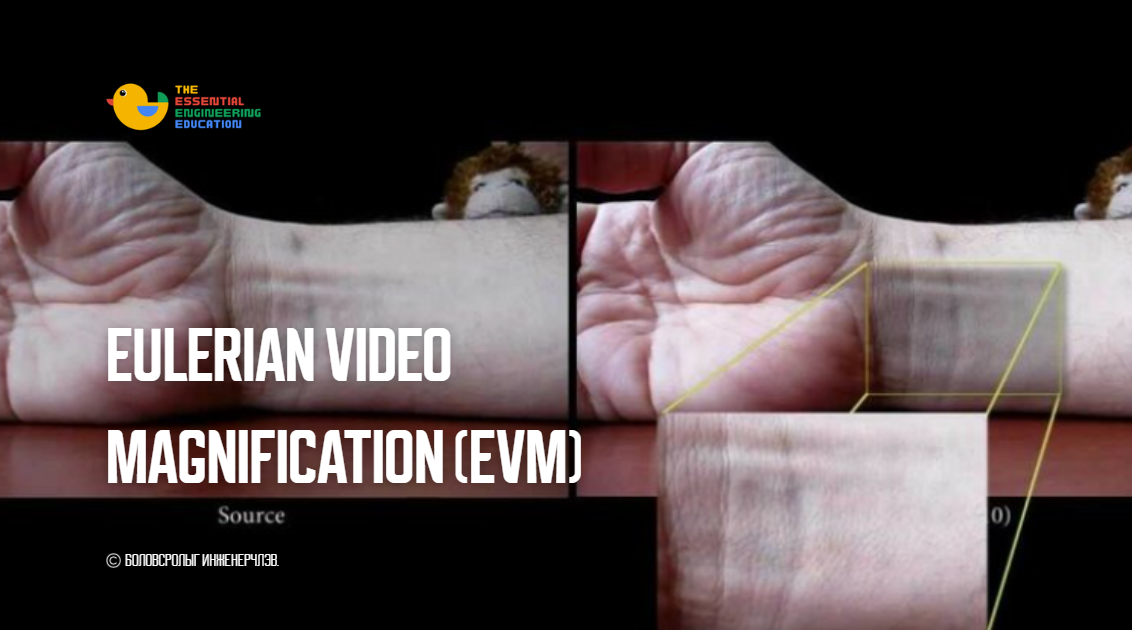
Хэлний загварууд ба тэдгээрийн хөгжил
Хэлний загвар (Language Model – LM) гэж юу вэ? Хэлний загварууд нь хүний хэл яриаг ойлгож, боловсруулах зорилготой хиймэл оюун ухааны чухал дэд салбар юм. Эдгээр загварууд нь их хэмжээний бичвэрэн өгөгдлөөс суралцаж, үгсийн болон өгүүлбэрийн хоорондын утгазүйн болон бүтцийн хамаарлыг тогтоодог. Суралцсан мэдлэг дээрээ үндэслэн хэлний загварууд нь шинэ бичвэр үүсгэх, орчуулах, хураангуйлах, асуултад […]
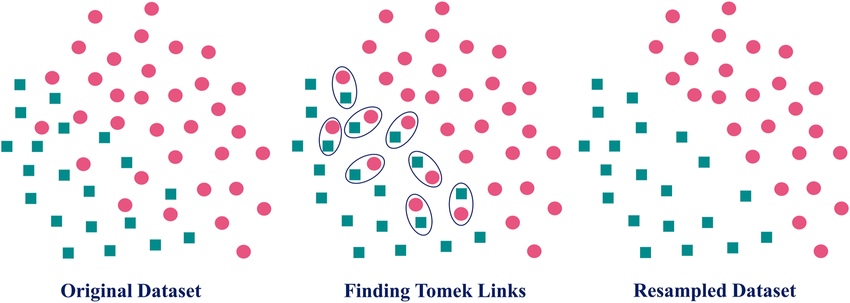
SMOTETomek аргаар тэнцвэргүй өгөгдөлтэй тэмцэх нь
Машин сургалтын бодит хэрэглээнд, жишээ нь залилах илрүүлэлт, өвчний оношлогоо зэрэгт тэнцвэргүй өгөгдөл (нэг ангилал нөгөөгөөсөө хавьгүй их тоотой байх) түгээмэл тохиолддог. Энэ нь загваруудыг олонхи ангиллын талд хэт нэг талыг барьсан байдлаар сургах хандлагатай болгож, цөөнхийн ангиллыг зөв таамаглах чадварыг сулруулдаг гэж өмнөх нийтлэлээрээ бид ярилцсан. Энэ асуудлыг шийдвэрлэх үр дүнтэй аргуудын нэг нь […]
ChatGPT ба эелдэг үгийн зардал
Та ChatGPT-д “баярлалаа” эсвэл “гуйя” гэж хэлдэг үү? Тэгвэл таны эелдэг байдал OpenAI-д жил бүр хэдэн арван сая долларын зардал нэмдэг гэдгийг компанийн гүйцэтгэх захирал Сэм Алтман дурдлаа. Учир нь энэ мэт жижиг боловч давтагддаг үгс AI-ийн боловсруулж буй өгөгдлийн хэмжээг өсгөж, илүү их цахилгаан, тооцооллын нөөц шаардаж эхэлдэг байна. Бидний ганц өгүүлбэрийн ард асар […]

Өгөгдлийн тэнцвэртэй байдал гэж юу вэ- Part1
Өнөөгийн машин сургалтын алгоритмууд нь том хэмжээний өгөгдөлд суурилан загварчлагдаж, янз бүрийн хэрэглээний талбарт өргөн ашиглагдаж байна. Гэсэн хэдий ч бодит амьдрал дээр өгөгдөл ихэвчлэн тэнцвэргүй (imbalanced) байдаг нь загварын гүйцэтгэлийг муутгаж, цөөн тооны (minority) ангиллын өгөгдлийг үл тоомсорлох хандлагыг бий болгодог. Энэхүү нийтлэлд бид өгөгдлийн тэнцвэржилтийн хэрэгцээ, ач холбогдлыг тайлбарлаж, түгээмэл хэрэглэгддэг аргачлал болох […]
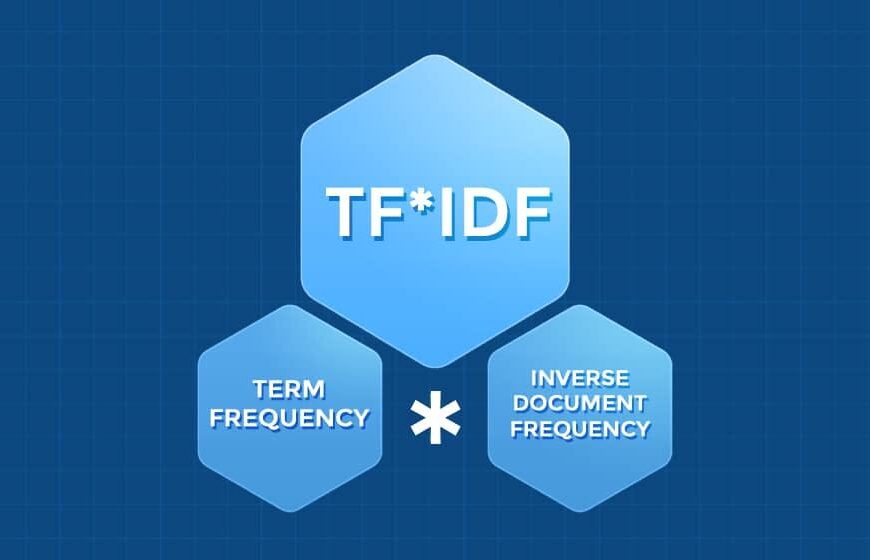
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF (Term Frequency – Inverse Document Frequency) нь NLP-(Natural Learning Processing) болон мэдээлэл хайлтын салбарт өргөн хэрэглэгддэг статистик арга юм. Энэ аргачлал нь тухайн тодорхойлсон үг нь документэд дахь давтамж болон нийт документийн хүрээн дэхь давтамжуудыг тодорхойлдог. TF-IDF хэрхэн ажилладаг вэ? Энэхүү аргачлал нь 2 үндсэн аргаар тогтоно.1. Term Frequency- TF Энэхүү томьёо нь үг […]